Spark的Stage划分及提交的源码分析 [TOC]
当触发一个RDD的action后,以count为例,调用关系如下:
org.apache.spark.rdd.RDD >>>> count
org.apache.spark.SparkContext >>>> runJob
org.apache.spark.scheduler.DAGScheduler >>>> runJob
org.apache.spark.scheduler.DAGScheduler >>>> submitJob
org.apache.spark.scheduler.DAGSchedulerEventProcessActor >>>> receive(JobSubmitted)
org.apache.spark.scheduler.DAGScheduler >>>> handleJobSubmitted
其中步骤五的DAGSchedulerEventProcessActor是DAGScheduler 的与外部交互的接口代理,DAGScheduler在创建时会创建名字为eventProcessActor的actor。这个actor的作用看它的实现就一目了然了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 def receive case JobSubmitted (jobId, rdd, func, partitions, allowLocal, callSite, listener, properties) =>case StageCancelled (stageId) => case JobCancelled (jobId) => case JobGroupCancelled (groupId) => case AllJobsCancelled => case ExecutorAdded (execId, host) => case ExecutorLost (execId) => case BeginEvent (task, taskInfo) => case GettingResultEvent (taskInfo) => case completion @ CompletionEvent (task, reason, _, _, taskInfo, taskMetrics) => case TaskSetFailed (taskSet, reason) => case ResubmitFailedStages =>
总结一下:org.apache.spark.scheduler.DAGSchedulerEventProcessActor的作用:可以把他理解成DAGScheduler的对外的功能接口。它对外隐藏了自己内部实现的细节,也更易于理解其逻辑;也降低了维护成本,将DAGScheduler的比较复杂功能接口化。
handleJobSubmitted org.apache.spark.scheduler.DAGScheduler >>>> handleJobSubmitted 首先会根据RDD创建 finalStage。finalStage,顾名思义,就是最后的那个Stage。然后创建job,最后提交。提交的job如果满足一下条件,那么它将以本地模式运行:
spark.localExecution.enabled设置为true
用户程序显式指定可以本地运行
finalStage的没有父Stage
仅有一个partition
3 和 4 的话主要为了任务可以快速执行
如果有多个stage或者多个partition的话,本地运行可能会因为本机的计算资源的问题而影响任务的计算速度。
要理解什么是Stage,首先要搞明白什么是Task。Task是在集群上运行的基本单位。一个Task负责处理RDD的一个partition。RDD的多个patition会分别由不同的Task去处理。当然了这些Task的处理逻辑完全是一致的。这一组Task就组成了一个Stage。有两种Task:
org.apache.spark.scheduler.ShuffleMapTask
org.apache.spark.scheduler.ResultTask
ShuffleMapTask根据Task的partitioner将计算结果放到不同的bucket中。而ResultTask将计算结果发送回Driver Application。一个Job包含了多个Stage,而Stage是由一组完全相同的Task组成的。最后的Stage包含了一组ResultTask。
在用户触发了一个action后,比如count,collect,SparkContext会通过runJob的函数开始进行任务提交。最后会通过DAG的event processor 传递到DAGScheduler本身的handleJobSubmitted,它首先会划分Stage,提交Stage,提交Task。至此,Task就开始在运行在集群上了。
一个Stage的开始就是从外部存储或者shuffle结果中读取数据;一个Stage的结束就是由于发生shuffle或者生成结果时。
创建finalStage handleJobSubmitted 通过调用newStage来创建finalStage:
1 2 finalStage = newStage(finalRDD, partitions.size, None , jobId, callSite)DAGScheduler >>>> newStage完成的;而创建一个shuffle stage,需要通过调用org.apache.spark.scheduler.DAGScheduler >>>> newOrUsedStage。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private def newStage RDD [_],Int ,Option [ShuffleDependency [_, _, _]],Int ,CallSite )Stage =val id = nextStageId.getAndIncrement()val stage =new Stage (id, rdd, numTasks, shuffleDep, getParentStages(rdd, jobId), jobId, callSite)
对于result 的final stage来说,传入的shuffleDep是None。
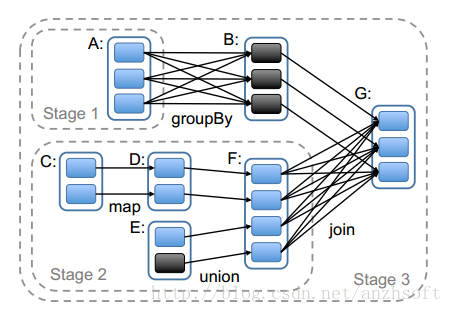
我们知道,RDD通过org.apache.spark.rdd.RDD >>>> getDependencies可以获得它依赖的parent RDD。而Stage也可能会有parent Stage。看一个RDD论文的Stage划分吧:
一个stage的边界,输入是外部的存储或者一个stage shuffle的结果;输入则是Job的结果(result task对应的stage)或者shuffle的结果。
上图的话stage3的输入则是RDD A和RDD F shuffle的结果。而A和F由于到B和G需要shuffle,因此需要划分到不同的stage。
从源码实现的角度来看,通过触发action也就是最后一个RDD创建final stage(上图的stage 3),我们注意到new Stage的第五个参数就是该Stage的parent Stage:通过rdd和job id获取:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 private def getParentStages RDD [_], jobId: Int ): List [Stage ] = {val parents = new HashSet [Stage ] val visited = new HashSet [RDD [_]] val waitingForVisit = new Stack [RDD [_]]def visit RDD [_]) {if (!visited(r)) {for (dep <- r.dependencies) {match {case shufDep: ShuffleDependency [_, _, _] => case _ =>while (!waitingForVisit.isEmpty) {
生成了finalStage后,就需要提交Stage了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 private def submitStage Stage ) {val jobId = activeJobForStage(stage)if (jobId.isDefined) {"submitStage(" + stage + ")" )if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {val missing = getMissingParentStages(stage).sortBy(_.id)"missing: " + missing)if (missing == Nil ) { "Submitting " + stage + " (" + stage.rdd + "), which has no missing parents" )else {for (parent <- missing) { else {"No active job for stage " + stage.id)
DAGScheduler将Stage划分完成后,提交实际上是通过把Stage转换为TaskSet,然后通过TaskScheduler将计算任务最终提交到集群。
接下来,将分析Stage是如何转换为TaskSet,并最终提交到Executor去运行的。
从org.apache.spark.scheduler.DAGScheduler >>>> submitMissingTasks开始,分析Stage是如何生成TaskSet的。
如果一个Stage的所有的parent stage都已经计算完成或者存在于cache中,那么他会调用submitMissingTasks来提交该Stage所包含的Tasks。
org.apache.spark.scheduler.DAGScheduler >>>> submitMissingTasks的计算流程如下:
首先得到RDD中需要计算的partition,对于Shuffle类型的stage,需要判断stage中是否缓存了该结果;对于Result类型的Final Stage,则判断计算Job中该partition是否已经计算完成。
序列化task的binary。Executor可以通过广播变量得到它。每个task运行的时候首先会反序列化。这样在不同的executor上运行的task是隔离的,不会相互影响。
为每个需要计算的partition生成一个task:对于Shuffle类型依赖的Stage,生成ShuffleMapTask类型的task;对于Result类型的Stage,生成一个ResultTask类型的task
确保Task是可以被序列化的。因为不同的cluster有不同的taskScheduler,在这里判断可以简化逻辑;保证TaskSet的task都是可以序列化的
通过TaskScheduler提交TaskSet。
TaskSet就是可以做pipeline的一组完全相同的task,每个task的处理逻辑完全相同,不同的是处理数据,每个task负责处理一个partition。pipeline,可以称为大数据处理的基石,只有数据进行pipeline处理,才能将其放到集群中去运行。对于一个task来说,它从数据源获得逻辑,然后按照拓扑顺序,顺序执行(实际上是调用rdd的compute)。
TaskSet是一个数据结构,存储了这一组task:
1 2 3 4 5 6 7 8 9 10 private [spark] class TaskSet ( val tasks: Array [Task [_]], val stageId: Int , val attempt: Int , val priority: Int , val properties: Properties ) val id: String = stageId + "." + attemptoverride def toString String = "TaskSet " + id
管理调度这个TaskSet的时org.apache.spark.scheduler.TaskSetManager,TaskSetManager会负责task的失败重试;跟踪每个task的执行状态;处理locality-aware的调用。
详细的调用堆栈如下:
org.apache.spark.scheduler.TaskSchedulerImpl >>>> submitTasks
org.apache.spark.scheduler.SchedulableBuilder >>>> addTaskSetManager
org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend >>>> reviveOffers
org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.DriverActor >>>> makeOffers
org.apache.spark.scheduler.TaskSchedulerImpl >>>> resourceOffers
org.apache.spark.scheduler.cluster.CoarseGrainedSchedulerBackend.DriverActor >>>> launchTasks
org.apache.spark.executor.CoarseGrainedExecutorBackend.receiveWithLogging >>>> launchTask
org.apache.spark.executor.Executor >>>> launchTask
首先看一下org.apache.spark.executor.Executor >>>> launchTask :
1 2 3 4 5 6 def launchTask ExecutorBackend , taskId: Long , taskName: String , serializedTask: ByteBuffer ) {val tr = new TaskRunner (context, taskId, taskName, serializedTask)
TaskRunner会从序列化的task中反序列化得到task,这个需要看 org.apache.spark.executor.Executor.TaskRunner >>>> run 的实现:task.run(taskId.toInt)。而task.run的实现是:
1 2 3 4 5 6 7 8 9 final def run(attemptId: Long): T = {new TaskContext(stageId , partitionId , attemptId , runningLocally = false ) Utils .HostName() Thread .Thread() if (_killed) {false )Task(context )
对于原来提到的两种Task,即
org.apache.spark.scheduler.ShuffleMapTask
org.apache.spark.scheduler.ResultTask
分别实现了不同的runTask:
org.apache.spark.scheduler.ResultTask >>>> runTask即顺序调用rdd的compute,通过rdd的拓扑顺序依次对partition进行计算:
1 2 3 4 5 6 7 8 9 10 11 12 13 override def runTask TaskContext ): U = {val ser = SparkEnv .get.closureSerializer.newInstance()val (rdd, func) = ser.deserialize[(RDD [T ], (TaskContext , Iterator [T ]) => U )](ByteBuffer .wrap(taskBinary.value), Thread .currentThread.getContextClassLoader)Some (context.taskMetrics)try {finally {
而org.apache.spark.scheduler.ShuffleMapTask >>>> runTask则是写shuffle的结果,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 override def runTask TaskContext ): MapStatus = {val ser = SparkEnv .get.closureSerializer.newInstance()val (rdd, dep) = ser.deserialize[(RDD [_], ShuffleDependency [_, _, _])](ByteBuffer .wrap(taskBinary.value), Thread .currentThread.getContextClassLoader)Some (context.taskMetrics)var writer: ShuffleWriter [Any , Any ] = null try {val manager = SparkEnv .get.shuffleManagerAny , Any ](dep.shuffleHandle, partitionId, context)Iterator [_ <: Product2 [Any , Any ]]]) return writer.stop(success = true ).getcatch {case e: Exception =>if (writer != null ) {false )throw efinally {
这两个task都不要按照拓扑顺序调用rdd的compute来完成对partition的计算,不同的是ShuffleMapTask需要shuffle write,以供child stage读取shuffle的结果。 对于这两个task都用到的taskBinary,即为在org.apache.spark.scheduler.DAGScheduler >>>> submitMissingTasks序列化的task的广播变量取得的。