SparkRDD的持久化机制详解
SparkRDD的持久化机制详解
[TOC]
RDD 持久化
Spark 中最重要的功能之一是跨操作 持久(或缓存)内存中的数据集。当你持久化一个 RDD 时,每个节点都会存储它在内存中计算的任何分区,并在该数据集(或从它派生的数据集)的其他操作中重用它们。这使得未来的动作可以更快(通常超过 10 倍)。缓存是迭代算法和快速交互使用的关键工具。
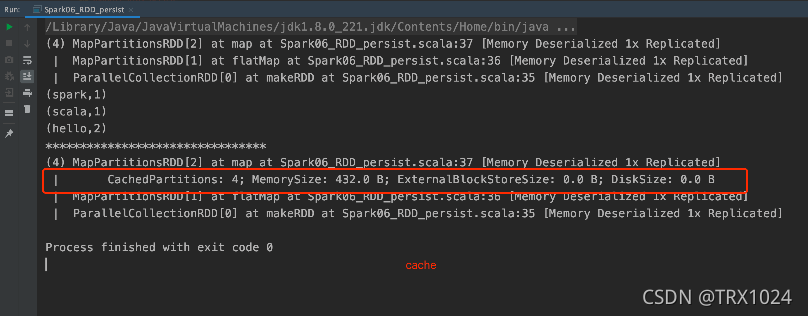
您可以使用 persist() 或 cache() 方法将 RDD 标记为持久化。第一次在动作中计算它时,它将保存在节点的内存中。 Spark 的缓存是容错的——如果 RDD 的任何分区丢失,它将使用最初创建它的转换自动重新计算。
此外,每个持久化的 RDD 可以使用不同的 存储级别 存储,例如,允许您将数据集持久化在磁盘上,将其持久化在内存中,但作为序列化的 Java 对象(以节省空间),跨节点复制它。这些级别是通过传递一个 StorageLevel 对象 (Scala, Java, [Python](https://spark.apache.org/ docs/latest/api/python/pyspark.html#pyspark.StorageLevel)) 到 persist()。 cache() 方法是使用默认存储级别的简写,即 StorageLevel.MEMORY_ONLY(将反序列化的对象存储在内存中)。完整的存储级别集是:
| Storage Level | Meaning |
|---|---|
| MEMORY_ONLY | 将 RDD 作为反序列化的 Java 对象存储在 JVM 中。 如果 RDD 不适合内存,某些分区将不会被缓存,并且会在每次需要时重新计算。 这是默认级别。 |
| MEMORY_AND_DISK | 将 RDD 作为反序列化的 Java 对象存储在 JVM 中。 如果 RDD 不适合内存,则存储不适合磁盘的分区,并在需要时从那里读取它们。 |
MEMORY_ONLY_SER (Java and Scala) |
将 RDD 存储为序列化 Java 对象(每个分区一个字节数组)。 这通常比反序列化对象更节省空间,尤其是在使用 快速序列化程序 时,但读取时更占用 CPU。 |
MEMORY_AND_DISK_SER (Java and Scala) |
与 MEMORY_ONLY_SER 类似,但将不适合内存的分区溢出到磁盘,而不是在每次需要时即时重新计算它们。 |
| DISK_ONLY | 仅将 RDD 分区存储在磁盘上。 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. | 与上述级别相同,但在两个集群节点上复制每个分区。 |
OFF_HEAP (experimental) |
类似于 MEMORY_ONLY_SER,但将数据存储在 堆外内存 中。 这需要启用堆外内存。 |
checkPoint
场景
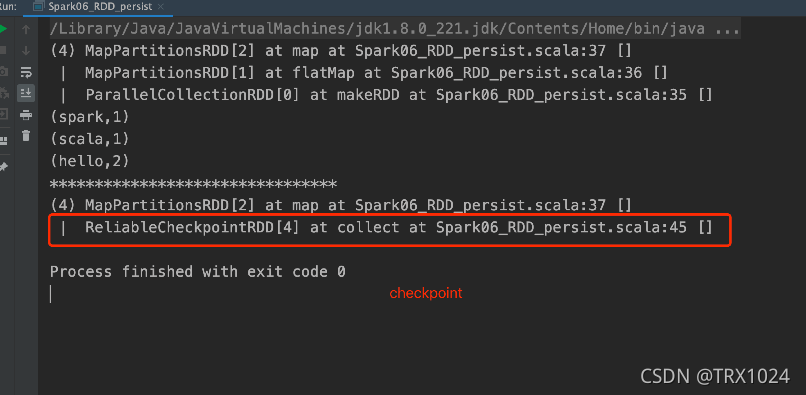
当业务场景非常复杂的时候,RDD的lineage(血统)依赖会非常的长,一旦血统较后面的RDD数据丢失的时候,Spark会根据血统依赖重新的计算丢失的RDD,这样会造成计算的时间过长,Spark提供了一个叫checkPoint的算子来解决这样的场景。
使用
为当前的RDD设置检查点。该算子会创建一个二进制的文件,并储存到checkPoint指定的目录中,该目录是用SparkContext.setCheckpointDir()设置的。在checkPoint的过程中,该RDD的所有依赖于父RDD中的信息将被全部移出。对 RDD 进行 checkpoint 操作并不会马上被执行,必须执行 Action 操作才能触发。
优点
- 持久化在HDFS上,默认的一备三机制使得持久化的备份数据更加的安全
- 切断RDD的依赖关系:当业务场景非常复杂,RDD的依赖关系非常的长的时候,当靠后的RDD数据丢失的时候,会经历比较长的计算过程,采用checkPoint会转为依赖checkPointRDD,阔以避免长的lineage(血统)重新计算
- 建议checkPoint之前进行cache操作,这样会将内存中的结果进行checkPoint,不用重新启动Job重新计算【优化】
原理
- 当FinalRDD执行Action类算子计算Job任务的时候,Spark会从finalRDD从后前回溯查看那些RDD使用checkPoint算子
- 将使用过checkpoint的算子标记
- Spark会自动的启动了一个job来重新计算标记了的RDD,并将计算的结果存入HDFS,然后切断了RDD的依赖关系
cache & persist & checkpoint 的特点和区别
特点
- cache:
- cache底层是调用.persist(StorageLevel.MEMORY_ONLY)
- 将数据临时存储在内存中进行数据重用
- 会在血缘关系中添加新的依赖,一旦出现问题,可以重头读取数据
- persist:
- 将数据临时存储在磁盘文件中进行数据重用
- 因为涉及到磁盘IO,性能较低,但是数据安全
- 如果作业执行完毕,临时保存的数据文件会丢失
- 会在血缘关系中添加新的依赖,一旦出现问题,可以重头读取数据
- checkpoint:
- 将数据长久的保存在磁盘文件中进行数据重用
- 因为涉及到磁盘IO,性能较低,但是数据安全
- 为了保证数据安全,所以一般情况下,会独立执行作业,
- 即调用检查点的rdd以前的流程都会重新执行一遍,所以效率比较低
- 为了能够提高效率,一般情况下,是需要和cache联合使用的
- 执行过程中,会切断血缘关系,重新建立新的血缘关系,
- 相当于将一个作业的数据源,由原文件切到检查点落盘的文件
- 下次重读数据时直接从checkpoint文件中读取
- checkpoint等同于改变数据源
区别
- cache/persist缓存只是将数据保存起来,不切断血缘依赖,只是加一条缓存的依赖关系。而checkpoint检查点会切断血缘依赖,checkpoint下游的RDD直接从checkpoint落盘的文件中读取数据,checkpoint等同于改变了数据源>。(如下图)
- cache/persist缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint的数据通常存储在HDFS等容错性强、高可用的文件系统中,可靠性高。
- 建议对checkpoint的RDD使用cache缓存,这样checkpoint的job只需从cache缓存中读取数据即可,否则需要从头计算一次RDD。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!