Spark中的宽窄依赖详解

Spark中的宽窄依赖详解
[TOC]
概述
RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖
具体细节
- 窄依赖
父RDD和子RDD partition之间的关系是一对一的。或者父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的。不会有shuffle的产生。父RDD的一个分区去到子RDD的一个分区。
宽依赖
父RDD与子RDD partition之间的关系是一对多。会有shuffle的产生。父RDD的一个分区的数据去到子RDD的不同分区里面。
其实区分宽窄依赖主要就是看父RDD的一个Partition的流向,要是流向一个的话就是窄依赖,流向多个的话就是宽依赖。看图理解:
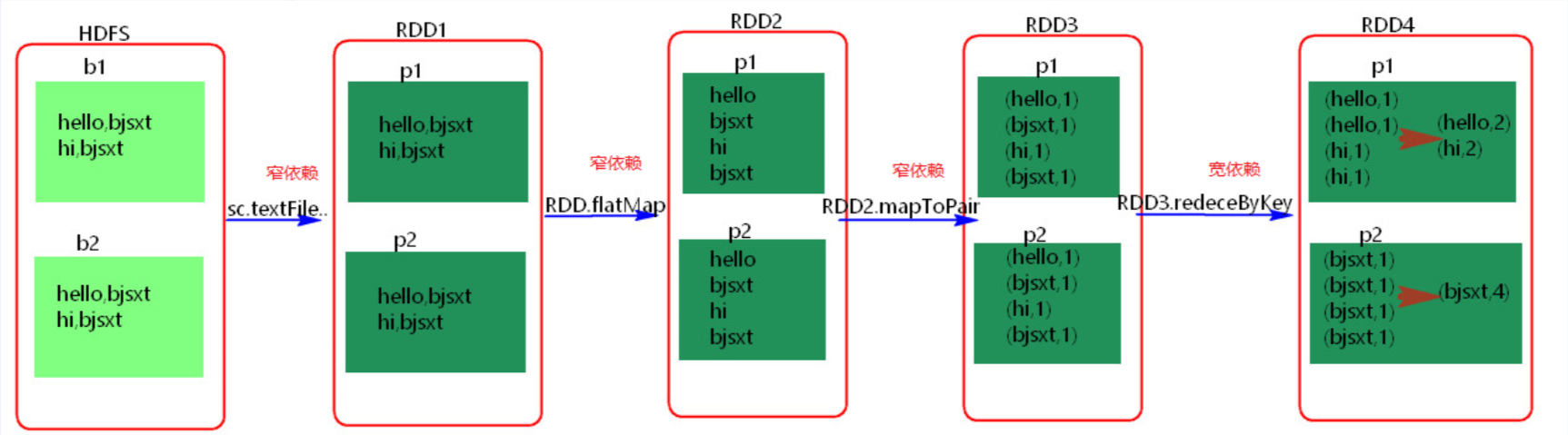
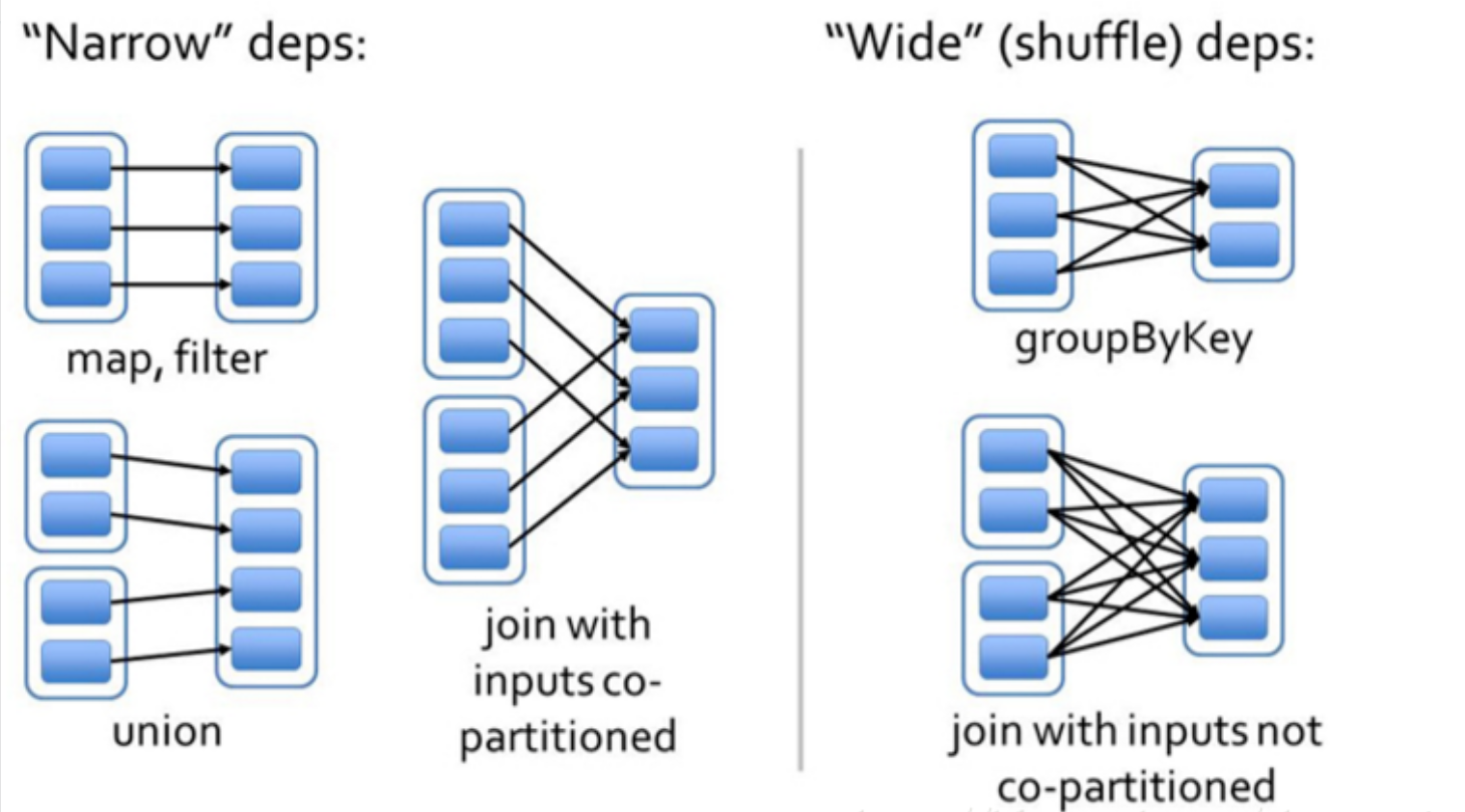
算子的宽窄依赖
对 RDD 进行 map、filter、union 等转换(Transformations)一般都是窄依赖
宽依赖一般是对 RDD 进行 groupByKey,reduceByKey 等操作,就是对 RDD 中的 partition 中的数据进行重新分区(shuffle)
join 操作可能是宽依赖也可能是窄依赖,当要对 RDD 进行 join 操作时,如果对 RDD 进行过重分区则为窄依赖,否则为宽依赖。
常见算子
宽依赖:groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition、distinct
distinct源码
1 | |
窄依赖:map,fiter,union,flatMap
Spark的Stage划分
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!