Kafka的基本概念及原理
Kafka的基本概念及原理
[TOC]
背景简介
Apache Kafka由著名职业社交公司LinkedIn开发,最初是被设计用来解决LinkedIn公司内部海量日志传输等问题。Kafka使用Scala语言编写,于2011年开源并进入Apache孵化器,2012年10月正式毕业,现在为Apache顶级项目。本文旨在使读者对Kafka有一个较为基本和全面的认识。
Kafka是什么?
Kafka是一个分布式数据流平台,可以运行在单台服务器上,也可以在多台服务器上部署形成集群。它提供了发布和订阅功能,使用者可以发送数据到Kafka中,也可以从Kafka中读取数据(以便进行后续的处理)。Kafka具有高吞吐、低延迟、高容错、可水平扩展、支持流数据处理等特点。
基本架构
下面介绍一下Kafka中常用的基本架构:
Broker
消息队列中常用的概念,在Kafka中指部署了Kafka实例的服务器节点。Topic
用来区分不同类型信息的主题。比如应用程序A订阅了主题t1,应用程序B订阅了主题t2而没有订阅t1,那么发送到主题t1中的数据将只能被应用程序A读到,而不会被应用程序B读到。Partition
每个topic可以有一个或多个partition(分区)。分区是在物理层面上的,不同的分区对应着不同的数据文件。Kafka使用分区支持物理上的并发写入和读取,从而大大提高了吞吐量。Record
实际写入Kafka中并可以被读取的消息记录。每个record包含了key、value和timestamp。Producer
生产者,用来向Kafka中发送数据(record)。Consumer
消费者,用来读取Kafka中的数据(record)。Consumer Group
一个消费者组可以包含一个或多个消费者。使用多分区+多消费者方式可以极大提高数据下游的处理速度。【每个分区只能被同一个group的一个consumer消费,但是阔以被多个group消费】-
producer的消息发送确认机制,这直接影响到Kafka集群的吞吐量和消息可靠性
-
分区中的所有副本统称为AR(Assigned Replicas)。所有与leader副本保持一定程度同步的副本(包括leader副本在内)组成ISR(In-Sync Replicas)
基本原理
Topic和数据日志
主题是同一类别的消息记录(record)的集合。在Kafka中,一个主题通常有多个订阅者。对于每个主题,Kafka集群维护了一个分区数据日志文件结构如下:
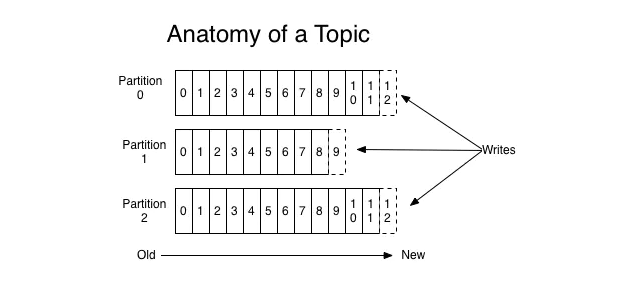
每个partition都是一个有序并且不可变的消息记录集合。当新的数据写入时,就被追加到partition的末尾。在每个partition中,每条消息都会被分配一个顺序的唯一标识,这个标识被称为offset,即偏移量。注意,Kafka只保证在同一个partition内部消息是有序的,在不同partition之间,并不能保证消息有序。
Kafka可以配置一个保留期限,用来标识日志会在Kafka集群内保留多长时间。Kafka集群会保留在保留期限内所有被发布的消息,不管这些消息是否被消费过。比如保留期限设置为两天,那么数据被发布到Kafka集群的两天以内,所有的这些数据都可以被消费。当超过两天,这些数据将会被清空,以便为后续的数据腾出空间。由于Kafka会将数据进行持久化存储(即写入到硬盘上),所以保留的数据大小可以设置为一个比较大的值。
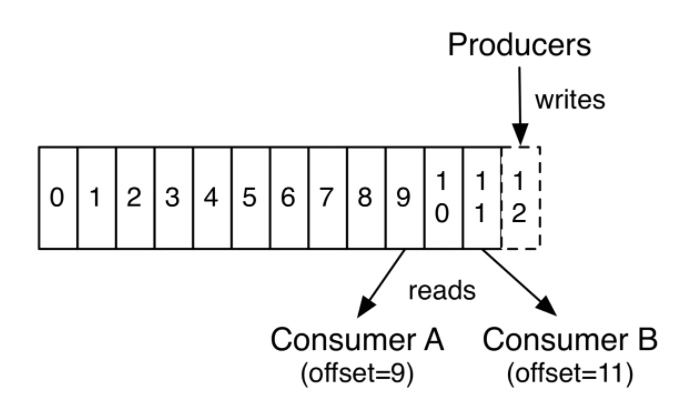
事实上,在单个消费者层面上,每个消费者保存的唯一的元数据就是它所消费的数据日志文件的偏移量。偏移量是由消费者来控制的,通常情况下,消费者会在读取记录时线性的提高其偏移量。不过由于偏移量是由消费者控制,所以消费者可以将偏移量设置到任何位置,比如设置到以前的位置对数据进行重复消费,或者设置到最新位置来跳过一些数据。
容错
每个topic的分区都可以分布在Kafka集群的不同服务器上。比如topic A有partition 0,1,2,分别分布在Broker 1,2,3上面。每个服务器都可以处理分布在它上面的分区的写入和读取操作。另外,每个分区也可以配置多个副本用来提高容错性。
每个partition有一个服务器充当“leader”,零至多个服务器充当“follower”。Leader会处理针对于这个分区的所有读写操作,而follower只是被动的从leader中复制数据。当leader挂掉了,那么原有的follower会自动选举出一个新的leader。每台服务器都会作为一些分区的leader,也会作为其他分区的follower,所以Kafka集群内的负载会比较均衡。
生产者
生产者可以将数据写入到选定的主题。生产者负责决定要将哪条记录写入到那个分区当中。阔以使用**轮询方式**,即每次取一小段时间的数据写入某个partition,下一小段的时间写入下一个partition;也可以使用一些分区函数(比如哈希),根据record的key值将记录写入不同的分区。
消费者
多个消费者实例可以组成一个消费者组,并用一个标签来标识这个消费者组。一个消费者组中的不同消费者实例可以运行在不同的进程甚至不同的服务器上。
如果所有的消费者实例都在同一个消费者组中,那么消息记录会被很好的均衡的发送到每个消费者实例。
如果所有的消费者实例都在不同的消费者组,那么每一条消息记录会被广播到每一个消费者实例。
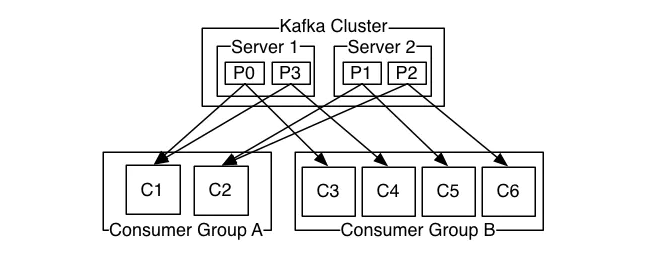
举个例子。如上图所示,一个两个节点的Kafka集群上拥有一个四个partition(P0-P3)的topic。有两个消费者组都在消费这个topic中的数据,消费者组A有两个消费者实例,消费者组B有四个消费者实例。
从图中我们可以看到,在同一个消费者组中,每个消费者实例可以消费多个分区,但是每个分区最多只能被消费者组中的一个实例消费。也就是说,如果有一个4个分区的主题,那么消费者组中最多只能有4个消费者实例去消费,多出来的都不会被分配到分区。其实这也很好理解,如果允许两个消费者实例同时消费同一个分区,那么就无法记录这个分区被这个消费者组消费的offset了。如果在消费者组中动态的上线或下线消费者,那么Kafka集群会自动调整分区与消费者实例间的对应关系。
使用场景
上面介绍了Kafka的一些基本概念和原理,那么Kafka可以做什么呢?目前主流使用场景基本如下:
消息队列(MQ)
在系统架构设计中,经常会使用消息队列(Message Queue)——MQ。MQ是一种跨进程的通信机制,用于上下游的消息传递,使用MQ可以使上下游解耦,消息发送上游只需要依赖MQ,逻辑上和物理上都不需要依赖其他下游服务。MQ的常见使用场景如流量削峰、数据驱动的任务依赖等等。在MQ领域,除了Kafka外还有传统的消息队列如ActiveMQ和RabbitMQ等。kafka与RabbitMQ的区别可见此文章
追踪网站活动
Kafka最出就是被设计用来进行网站活动(比如PV、UV、搜索记录等)的追踪。可以将不同的活动放入不同的主题,供后续的实时计算、实时监控等程序使用,也可以将数据导入到数据仓库中进行后续的离线处理和生成报表等。
Metrics
Kafka经常被用来传输监控数据。主要用来聚合分布式应用程序的统计数据,将数据集中后进行统一的分析和展示等。
日志聚合
很多人使用Kafka作为日志聚合的解决方案。日志聚合通常指将不同服务器上的日志收集起来并放入一个日志中心,比如一台文件服务器或者HDFS中的一个目录,供后续进行分析处理。相比于Flume和Scribe等日志聚合工具,Kafka具有更出色的性能。
kafka的复制机制
Kafka 的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的 follower 副本都复制完,这条消息才会被确认为已成功提交,这种复制方式极大地影响了性能。而在异步复制方式下,follower副本异步地从leader副本中复制数据,数据只要被leader副本写入就被认为已经成功提交。在这种情况下,如果follower副本都还没有复制完而落后于leader副本,突然leader副本宕机,则会造成数据丢失。Kafka使用的这种ISR的方式则有效地权衡了数据可靠性和性能之间的关系。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!