PyHDFS的方法操作详解
PyHDFS
[TOC]
安装
安装hadoop
关于hadoop的安装配置会在另一篇文章中介绍,这里只介绍python的hdfs库的安装.
安装hdfs库
所有python的三方模块均采用pip来安装.
1 | |
hdfs库的使用
下面将介绍hdfs库的方法列表,并会与hadoop自带的命令行工具进行比较
1 | |
list
作用
list()会列出hdfs指定路径的所有文件信息,接收两个参数
参数
- hdfs_path 要列出的hdfs路径
- status 默认为False,是否显示详细信息
应用
查看hdfs根目录下的文件信息,等同于hdfs dfs -ls /
1 | |
status
作用
查看文件或者目录状态
参数
- hdfs_path 要列出的hdfs路径
- strict 是否开启严格模式,严格模式下目录或文件不存在不会返回None,而是raise
应用
1 | |
checksum
作用
获取hdfs文件的校验和
参数
- hdfs_path 要列出file的hdfs路径
应用
1 | |
parts
作用
列出路径下的part file,接收三个参数
参数
- hdfs_path 要列出的hdfs路径
- parts 要显示的parts数量 默认全部显示,part名称相同,去重后显示
- status 默认为False,是否显示详细信息
应用
1 | |
content
作用
列出目录或文件详情,接收两个参数
参数
- hdfs_path 要列出的hdfs路径
- strict 是否开启严格模式,严格模式下目录或文件不存在不会返回None,而是raise
应用
1 | |
makedirs
作用
创建目录,同hdfs dfs -mkdir与hdfs dfs -chmod的结合体,接收两个参数
参数
- hdfs_path hdfs路径
- permission 文件权限
应用
1 | |
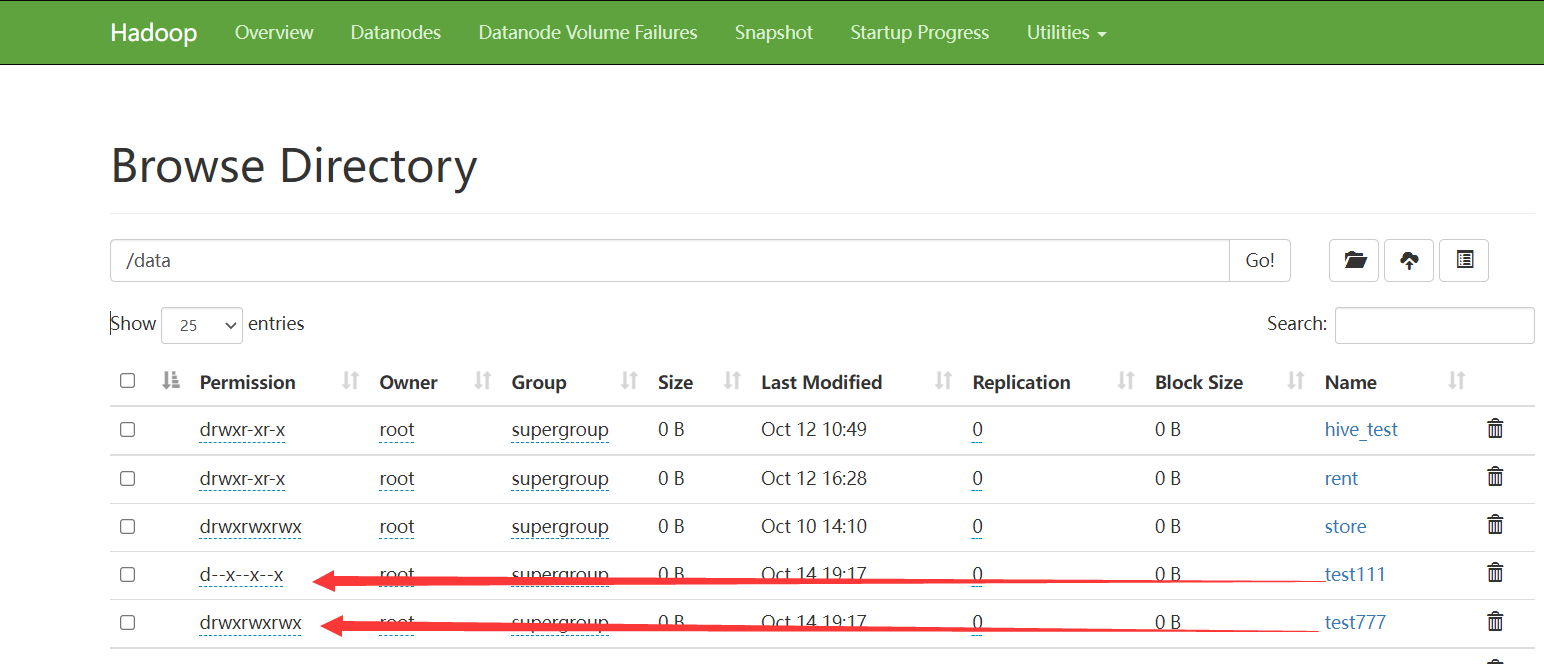
rename
作用
文件或目录重命名,接收两个参数
参数
- hdfs_src_path 原始路径或名称
- hdfs_dst_path 修改后的文件或路径
应用
1 | |
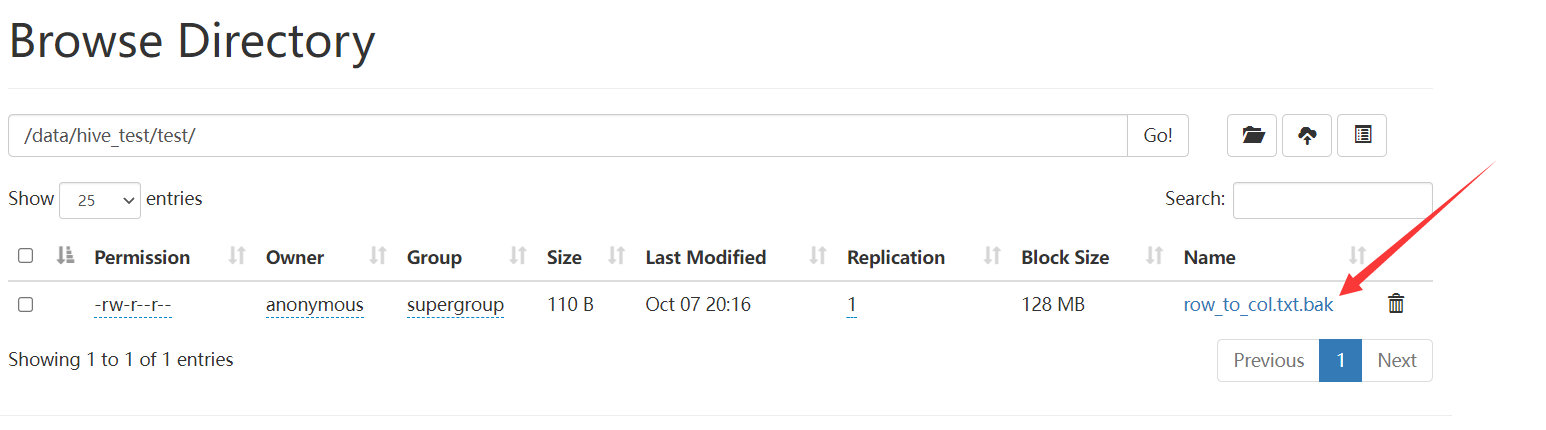
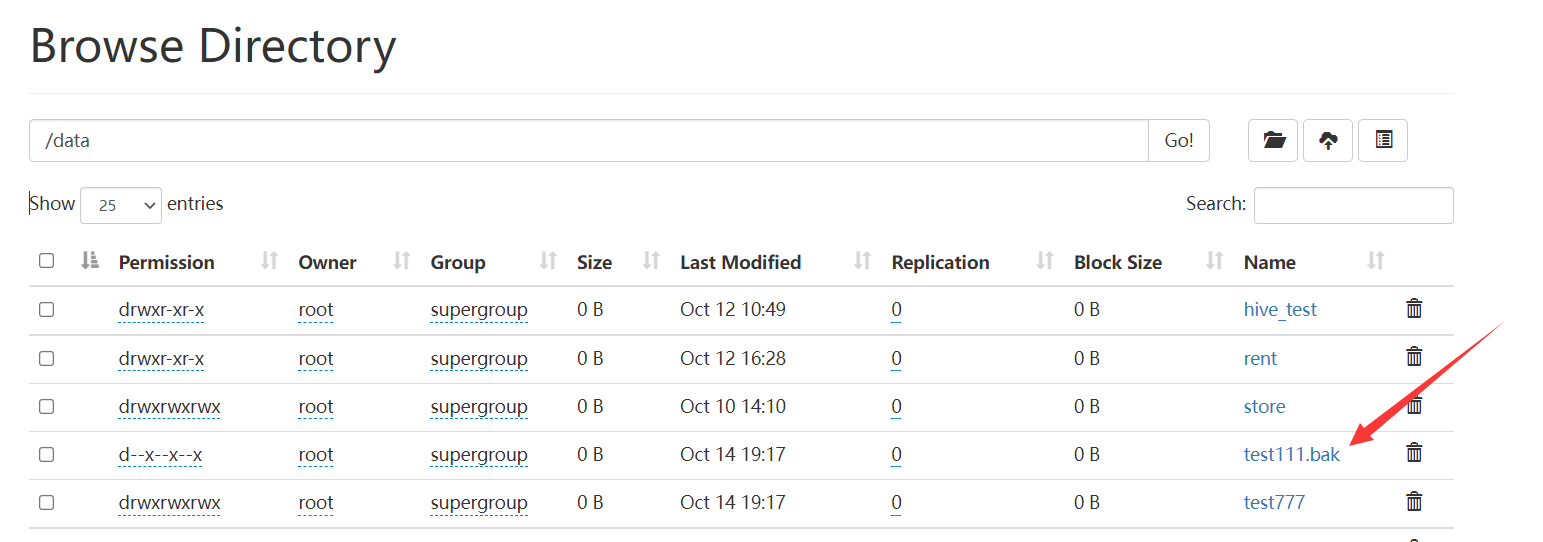
resolve
作用
返回绝对路径,接收一个参数hdfs_path
参数
- hdfs_path 要列出file的hdfs路径 ,若存在多个重名的文件,则返回路径深度最浅的路径
应用
1 | |
set_replication
作用
设置文件在hdfs上的副本(datanode上)数量,接收两个参数,集群模式下的hadoop默认保存3份
参数
- hdfs_path hdfs路径
- replication 副本数量
应用
1 | |
read
作用
读取文件信息 类似与 hdfs dfs -cat hfds_path,参数如下:
参数
- hdfs_path hdfs路径
- offset 读取位置
- length 读取长度
- buffer_size 设置buffer_size 不设置使用hdfs默认100MB 对于大文件 buffer够大的化 sort与shuffle都更快
- encoding 指定编码
- chunk_size 字节的生成器,必须和encodeing一起使用 满足chunk_size设置即 yield
- delimiter 设置分隔符 必须和encodeing一起设置
- progress 读取进度回调函数 读取一个chunk_size回调一次
应用
1 | |
1 | |
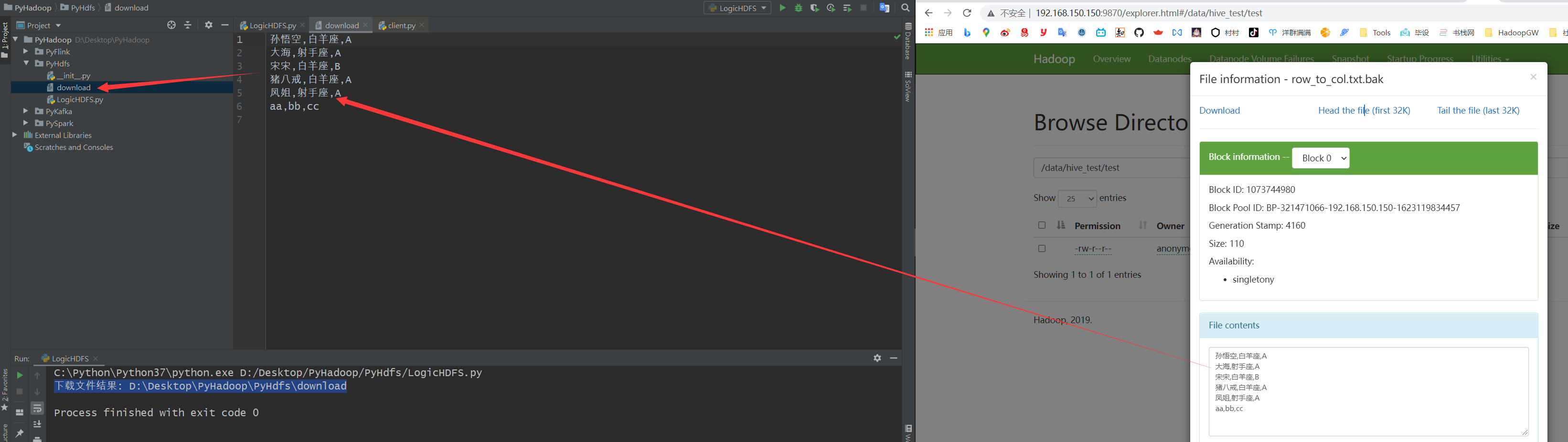
download
作用
从hdfs下载文件到本地,参数列表如下.
参数
- hdfs_path hdfs路径
- local_path 下载到的本地路径
- overwrite 是否覆盖(如果有同名文件) 默认为Flase
- n_threads 启动线程数量,默认为1,不启用多线程
- temp_dir下载过程中文件的临时路径
- **kwargs其他属性
应用
1 | |
upload
作用
上传文件到hdfs 同hdfs dfs -copyFromLocal local_file hdfs_path,参数列表如下:
参数
- hdfs_path, hdfs上位置
- local_path, 本地文件位置
- n_threads=1 并行线程数量 temp_dir=None, overwrite=True或者文件已存在的情况下的临时路径
- chunk_size=2 ** 16 块大小
- progress=None, 报告进度的回调函数 完成一个chunk_size回调一次 chunk_size可以设置大点 如果大文件的话
- cleanup=True, 上传错误时 是否删除已经上传的文件
- **kwargs 上传的一些关键字 一般设置为 overwrite 来覆盖上传
应用
1 | |
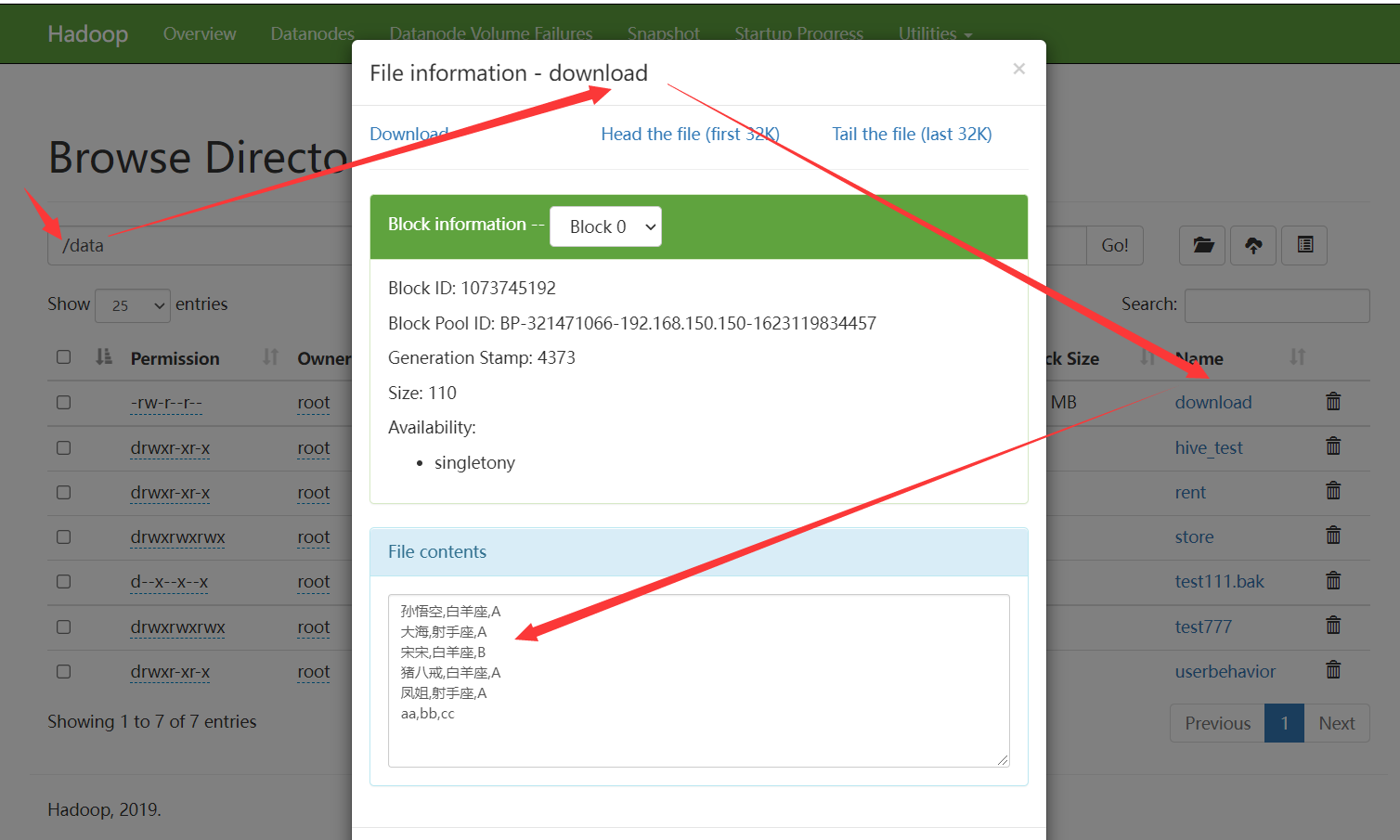
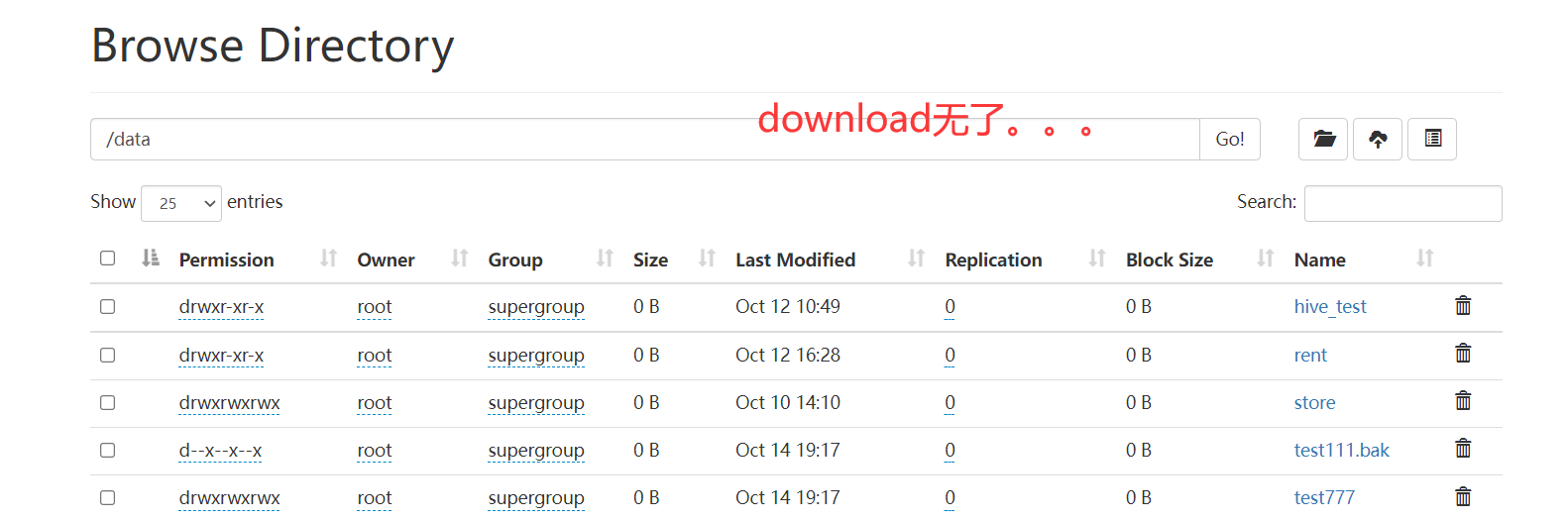
delete
作用
删除文件,接收三个参数【等同hdfs dfs -rm (-r)】
参数
- hdfs_path
- recursive=False 是否递归删除
- skip_trash=True 是否移到垃圾箱而不是直接删除 hadoop 2.9+版本支持
应用
1 | |
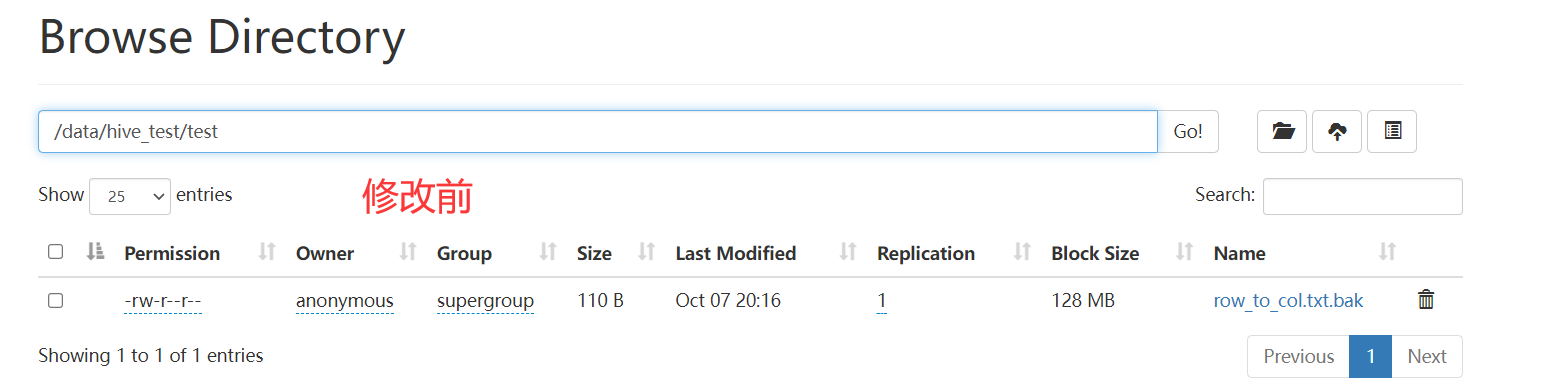
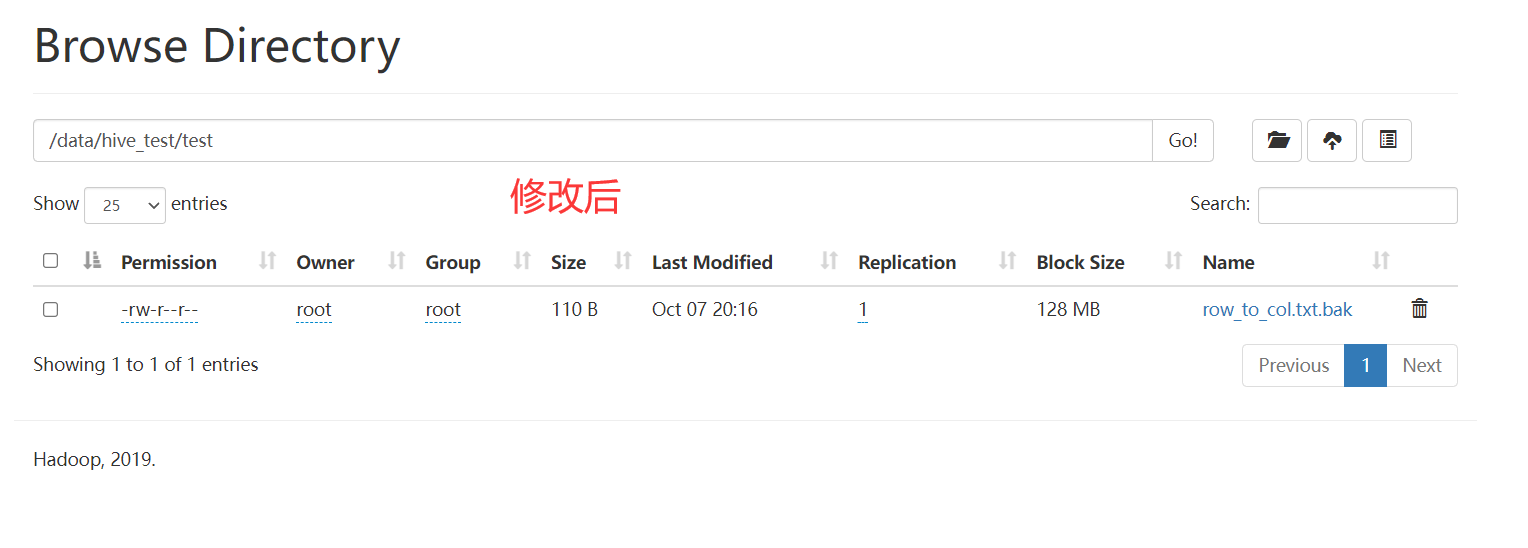
set_owner
作用
类似与 hdfs dfs -chown root root hdfs_path修改目录或文件的所属用户,用户组,接收三个参数
参数
- hdfs_path hdfs路径
- owner 用户
- group 用户组
注意:对于默认用户,只能修改自己的文件.
应用
1 | |
set_permission
作用
修改权限,类似于hdfs dfs -chmod 777 hdfs_path,接收两个参数
参数
- hdfs_path hdfs路径
- permission 权限
应用
1 | |
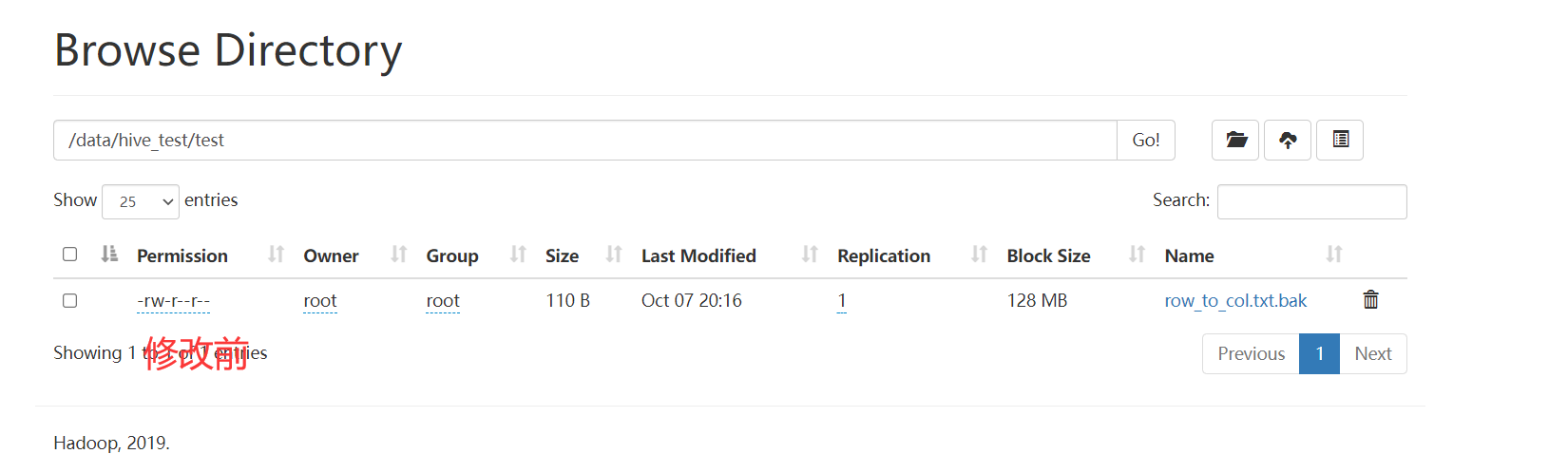
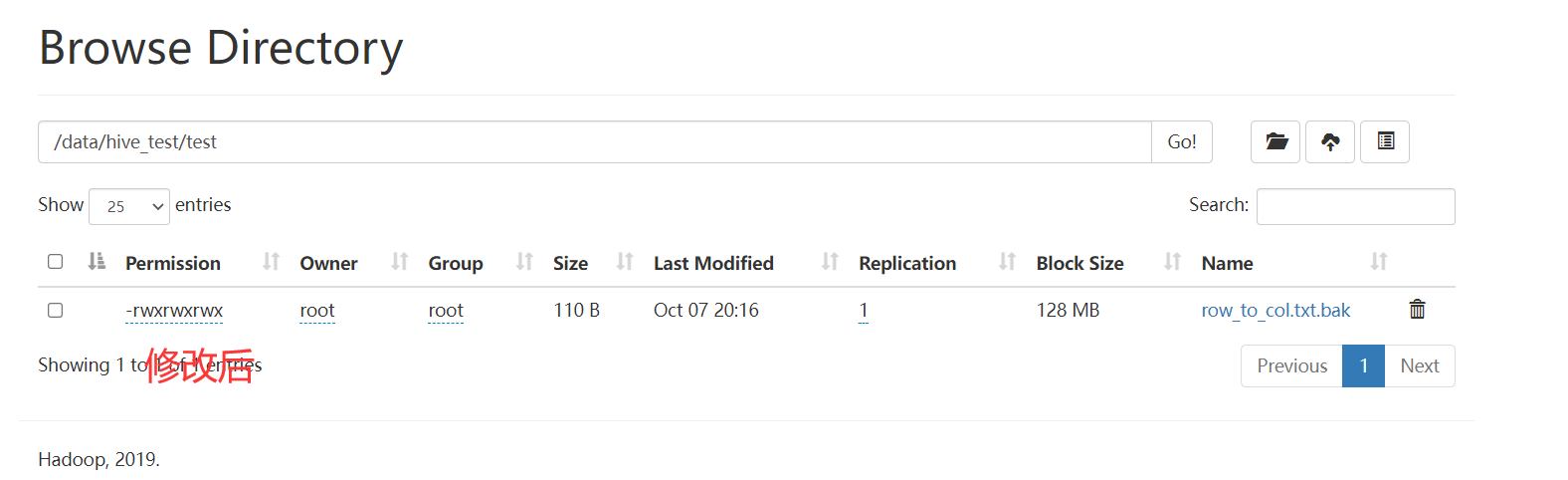
set_acl与acl_status
查看和修改访问权限控制 需要开启acl支持
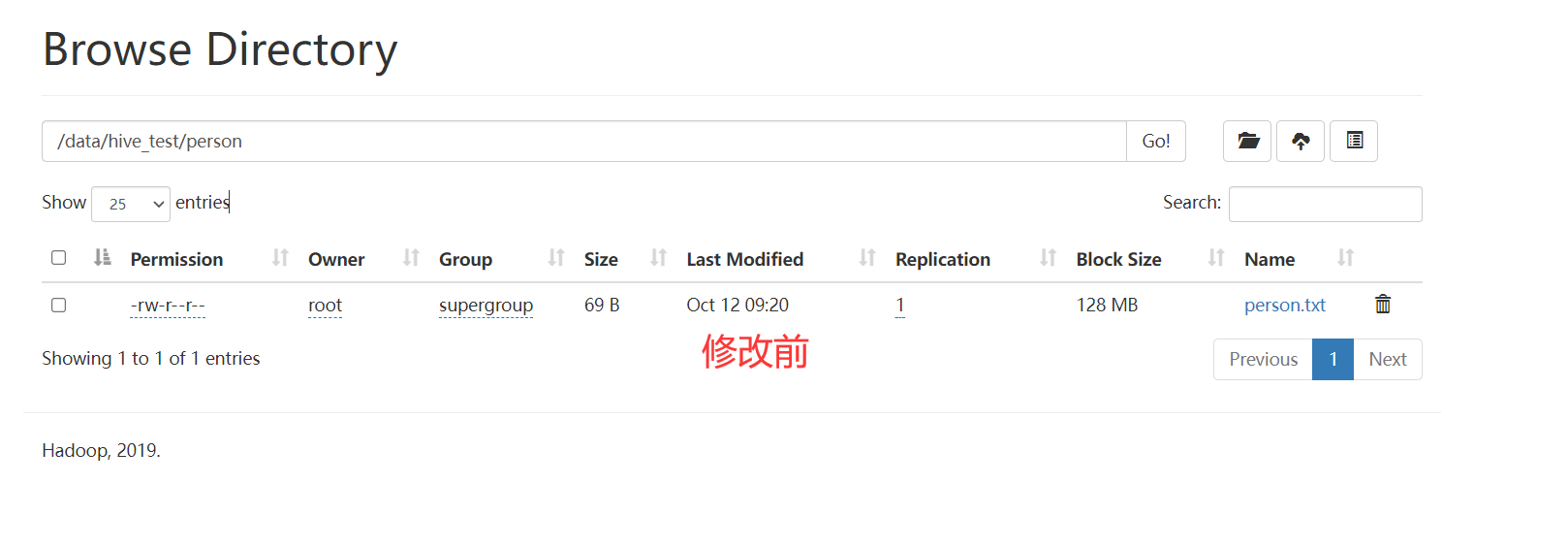
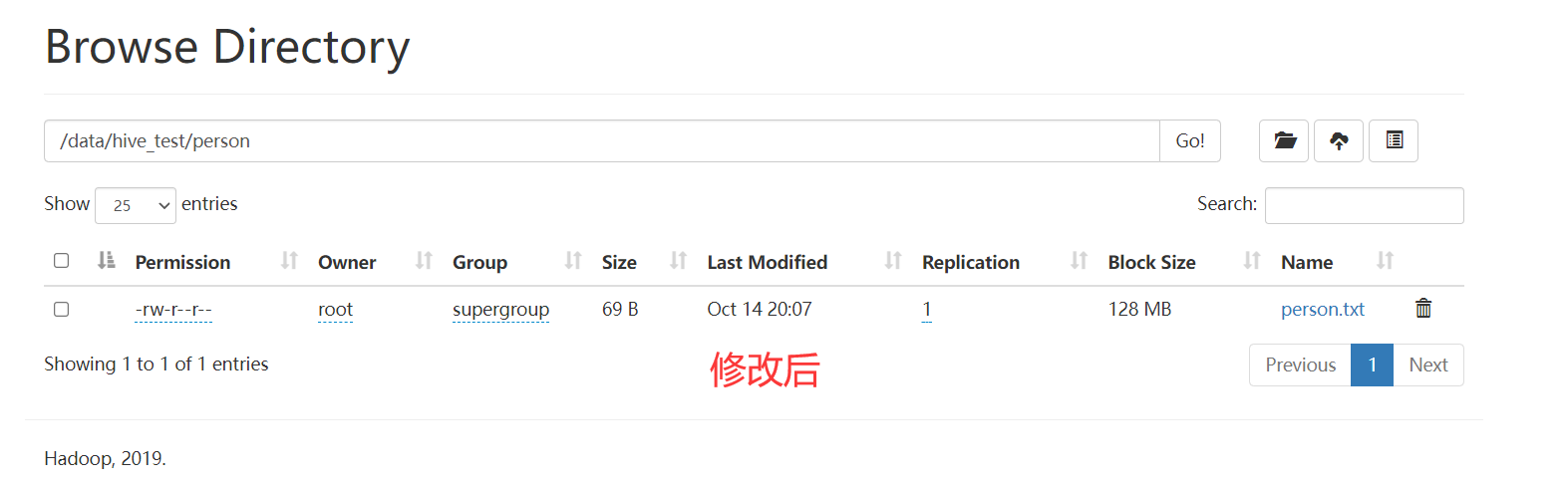
set_times
作用
设置文件时间,接收参数如下:
参数
- hdfs_path: hdfs路径.
- access_time: 最后访问时间 时间戳 毫秒
- modification_time: 最后修改时间 时间戳 毫秒
应用
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!