HBase的特点及其原理
HBase的特点及其原理
[TOC]
- 大:一个表可以有上十亿行,上百万列
- HBase是一个分布式的基与列式存储的数据库,基于Hadoop的hdfs存储,zookeeper进行管理
- HBase适合存储半结构化或者非结构化的数据,对于数据结构字段不够确定或者杂乱无章很难按一个概念去抽取的数据
- 稀疏:对于为空(null)的列,并不占用存储空间
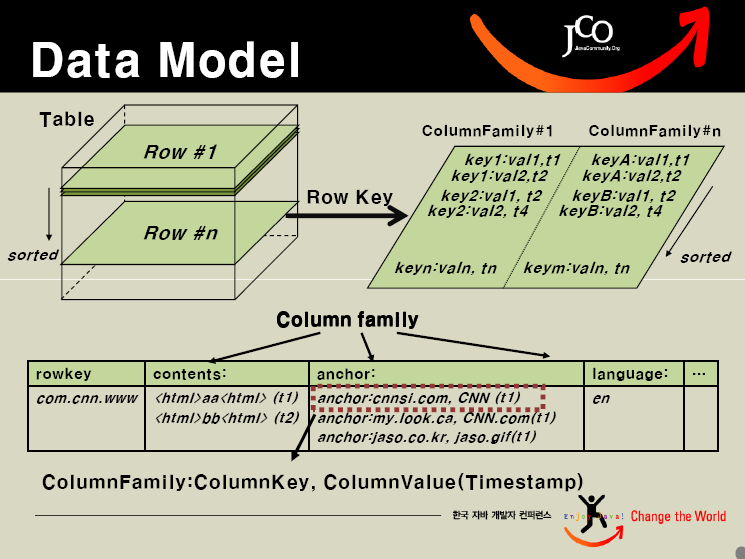
- 基于的表包含rowkey,时间戳,和列族。新写入数据时,时间戳更新,同时可以查询到以前的版本
- HBase的数据储存于HDFS上,但是阔以做随机读写操作的数据库
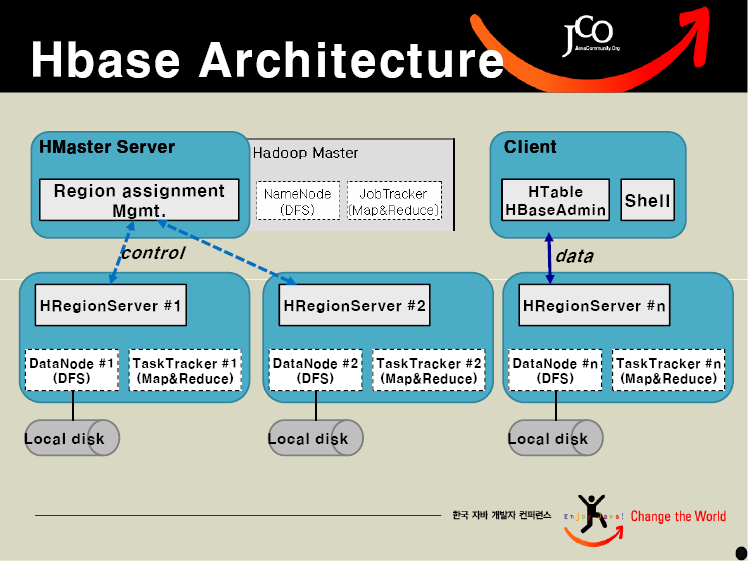
- HBase是主从架构。Hmaster作为主节点,Hregionserver作为从节点
所以基本上述的HBase特点,提出以下疑问:
1、HBase为什么能实现随机读写?
HBase是一个阔以随机读写的数据库,而它所基于的持久化层HDFS却是要么新增,要么整个删除,不能修改的系统。那么HBase是怎么实现增删改查的呢?
为什么要进行文件合并呢?
原因
HBase是一种Log-Structured Merge Tree 的架构模式,HBase几乎总是在做新增操作。
当你做新增操作新增一个单元格的时候,HBase在HDFS上就新增一条数据;
当你做修改操作修改一个单元格的时候,HBase又在HDFS上新增一条数据,只是版本号比之前那个大(或者自己定义)
当你做删除操作参数一个单元格的时候,HBase还是在HDFS上新增一条数据,只是这条数据没有Value,类型为DELETE,这条数据叫
墓碑标记(Tombstone)。那么真正的修改和删除操作发生在什么时候呢?
由于数据库在是使用过程中积累了很多增删改查操作,数据的连续性和顺序性必然会被破坏。为了提升性能,HBase每间隔一段时间都会进行一次合并(Compaction),合并的对象为HFile文件。
另外随着数据的不断写入增多,Flush次数也会不断的增多,进而HFile数据文件就会越来越多。然而,太多的数据文件会导致数据查询IO次数增多,因此HBase尝试着不断对这些文件进行合并
总结如下:
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile,影响查询性能。为了减少HFile的个数,以及清理掉过期和删除的数据,会进行StoreFile Compaction。
2、HFile合并
HFile合并理由上面已说。
Compaction分为两种,分别是Minor Compaction和Major Compaction
Minor Compaction
会将临近的若干个较小的HFile合并成一个较大的HFile,但【不会】清理过期和删除的数据。(128M以下称为小文件,小文件达到3个时合并成一个大文件),这种合并触发的频率比较高
Major Compaction
会将一个Store下的所有的HFile合并成一个大HFile,并且【会】清理掉过期和删除的数据。(每隔7天将所有的hfile合并成一个大文件,实际应用中一般关闭此项,自己手动Major Compaction,命令为major_compact ‘表名’,因为非常消耗性能)
3、Region Split(文件拆分)
原因
默认情况下,每个Table起初只有一个Region,随着数据的不断写入,压缩也会造成整体StoreFile变得很大,所以对于Region维度来说,会自动进行拆分。刚拆分时,两个子Region都位于当前的Region Server,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的Region Server。
那么问题来了,何时对文件进行拆分呢?
拆分时机
0.94版本之前
使用的是ConstantSizeRegionSplitPolicy策略
当1个region中的某个Store下所有StoreFile的总大小超过hbase.hregion.max.filesize(10G),该Region就会进行拆分。
0.94版本-2.0版本
使用的是IncreasingToUpperBoundRegionSplitPolicy策略
当1个Region中的某个Store下所有StoreFile的总大小超过Min(R^3 * “hbase.hregion.memstore.flush.size”,hbase.hregion.max.filesize”),该Region就会进行拆分。
其中R为当前Region Server中该Region所属Table的Region个数(一个表可能分成多个Region)。
2.0版本
使用的是SteppingSplitPolicy策略
当前RegionServer中属于该Table的Region个数为1,分裂阈值等于flushSize2,也就是(1282)M,否则为hbase.hregion.max.filesize(10G)
4、HBase适合存储哪类数据?
最适合使用Hbase存储的数据是非常稀疏的数据(非结构化或者半结构化的数据)
Hbase之所以擅长存储这类数据,是因为Hbase是column-oriented列导向的存储机制,而我们熟知的RDBMS都是row- oriented行导向的存储机制。
在列导向的存储机制下对于Null值得存储是不占用任何空间的
Hbase适合存储非结构化的稀疏数据的另一原因是他对列集合 column families 处理机制。 打个比方,ruby和python这样的动态语言和c++、java类的编译语言有什么不同? 对于我来说,最显然的不同就是你不需要为变量预先指定一个类型。Ok ,现在Hbase为未来的DBA也带来了这个激动人心的特性,你只需要告诉你的数据存储到Hbase的那个column families 就可以了,不需要指定它的具体类型:char,varchar,int,tinyint,text等等。
Hbase还有很多特性,比如不支持join查询,但你存储时可以用:parent-child tuple(不是很懂) 的方式来变相解决。
由于它是Google BigTable的 Java 实现,你可以参考一下:google bigtable 。
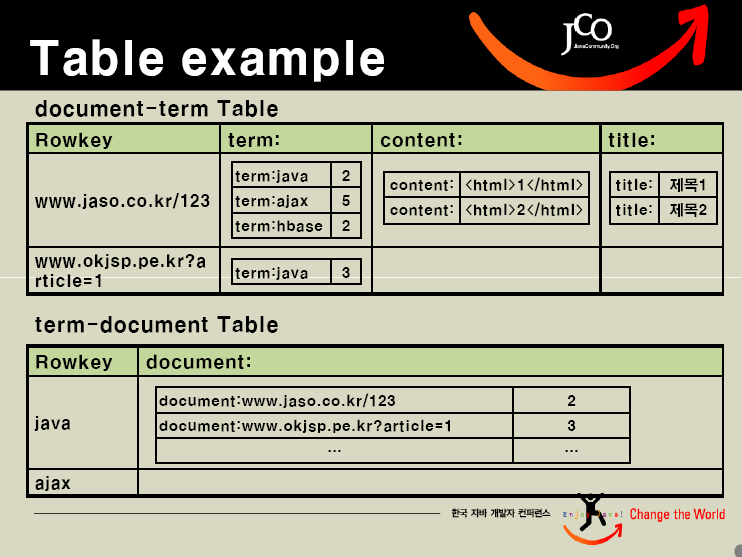
下面3副图是Hbase的架构、数据模型和一个表格例子,你也可以从:Hadoop summit 上 获取更多的信息。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!