Hive自定义函数 [TOC]
为什么需要自定义函数
hive的内置函数满足不了所有的业务需求。
hive提供很多的模块可以自定义功能,比如:自定义函数、serde、输入输出格式等。
常见的自定义函数
UDF:用户自定义函数,user defined function。一对一的输入输出。(最常用的)。
UDTF:用户自定义表生成函数。user defined table-generate function.一对多的输入输出。lateral view explode
UDAF:用户自定义聚合函数。user defined aggregate function。多对一的输入输出 count sum max。
自定义函数的实现 首先创建Maven工程,并在pom.xml中引入hive依赖
1 2 3 4 5 <dependency > <groupId > org.apache.hive</groupId > <artifactId > hive-exec</artifactId > <version > 3.1.2</version > </dependency >
1、UDF 定义UDF函数要注意下面几点:
继承org.apache.hadoop.hive.ql.exec.UDF
重写evaluate(),这个方法不是由接口定义的,因为它可接受的参数的个数,数据类型都是不确定的。Hive会检查UDF,看能否找到和函数调用相匹配的evaluate()方法
案例一 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import org.apache.hadoop.hive.ql.exec.UDF;import java.text.DateFormat;import java.text.SimpleDateFormat;import java.util.Calendar;import java.util.HashMap;import java.util.Map;public class DateNowBoundary extends UDF private final int [] PU = {7 ,30 ,30 ,180 ,360 };private final Map<String, Integer> m = new HashMap<>();private DateFormat d = new SimpleDateFormat("yyy-MM-dd" );private Calendar c = Calendar.getInstance();public DateNowBoundary () "W" , 0 );"M" , 1 );"Q" , 2 );"H" , 3 );"Y" , 4 );public String evaluate (String part) try {if (!m.containsKey(part)) {throw new Exception("unsupported part exception : part must be Y(year) Q(quarter) M(month) or W(week)!!!" );return d.format(c.getTime());catch (Exception e){return d.format(c.getTime());
案例二 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 import org.apache.hadoop.hive.ql.exec.UDF;import sun.misc.Cleaner;import java.text.DateFormat;import java.text.ParseException;import java.text.SimpleDateFormat;import java.util.Calendar;import java.util.regex.Pattern;public class DatePartBoundary extends UDF private Calendar c = Calendar.getInstance();private DateFormat d = new SimpleDateFormat("yyy-MM-dd" );private Pattern p = Pattern.compile("\\d+" );public String evaluate (Object date,String part,boolean first) int day = -1 , month = -1 , year = -1 ;try {if (p.matcher(date.toString()).matches())else switch (part){case "Y" : case "Q" : case "M" :1 ;switch (part){case "Y" :1 : 12 ;break ;case "Q" :1 )/3 ) * 3 + (first ? +1 : +3 );break ;1 );1 : 31 ;if (!first) {switch (month){case 4 : case 6 : case 9 : case 11 :30 ;break ;case 2 :4 ==0 && year%100 !=0 || year%400 ==0 ? 29 : 28 ;break ;break ;case "W" :int wd = c.get(Calendar.DAY_OF_WEEK) - 1 ;0 ? 7 : wd;if (first)1 ));else 7 -wd));break ;default :throw new Exception("unsupported part exception : part must be Y(year) Q(quarter) M(month) or W(week)!!!" );catch (Exception e) {return null ;return d.format(c.getTime());
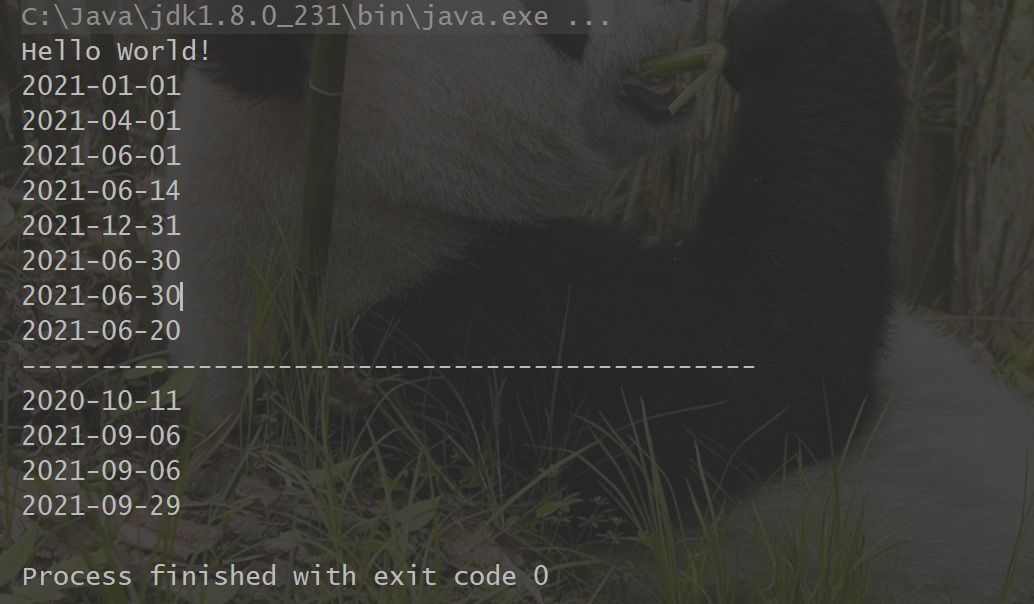
run案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import hive.udf.DateNowBoundary;import hive.udf.DatePartBoundary;import java.util.Calendar;public class App public static void main ( String[] args ) {assert args.length==2 ;"Hello World!" );new DatePartBoundary();"2021-6-18" , "Y" , true ));"2021-6-18" , "Q" , true ));"2021-6-18" , "M" , true ));"2021-6-18" , "W" , true ));"2021-6-18" , "Y" , false ));"2021-6-18" , "Q" , false ));"2021-6-18" , "M" , false ));"2021-6-18" , "W" , false ));"----------------------------------------------" );new DateNowBoundary();"Y" ));"M" ));"Q" ));"W" ));
结果如图:
2、UDTF UDTF是一对多的输入输出,实现UDTF需要完成下面步骤
继承org.apache.hadoop.hive.ql.udf.generic.GenericUDF
重写initlizer()、getdisplay()、evaluate()
执行流程如下:
UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息(返回个数,类型)。
初始化完成后,会调用process方法,真正的处理过程在process函数中,在process中,每一次forward()调用产生一行;如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数。
最后close()方法调用,对需要清理的方法进行清理。
案例一 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import org.apache.hadoop.hive.ql.exec.UDFArgumentException;import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;import org.apache.hadoop.hive.ql.metadata.HiveException;import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;import java.util.ArrayList;public class ParseMapUDTF extends GenericUDTF @Override public void close () throws HiveException @Override public StructObjectInspector initialize (ObjectInspector[] args) throws UDFArgumentException {if (args.length != 1 ) {throw new UDFArgumentLengthException(" 只能传入一个参数" );new ArrayList<String>();new ArrayList<ObjectInspector>();"map" );"key" );return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNameList,fieldOIs);@Override public void process (Object[] args) throws HiveException 0 ].toString();";" );for (int i=0 ; i<paramString.length; i++) {try {":" );catch (Exception e) {continue ;
打包加载 对上述命令源文件打包为udf.jar,拷贝到服务器的/hivedata/目录
在Hive客户端把udf.jar加入到hive中,如下:
1 add jar /hivedata/udf.jar;
创建临时函数 在Hive客户端创建函数
1 2 3 4 create temporary function parseMap as 'com.qf.hive.ParseMapUDTF' ; functions ;
测试临时函数 1 select parseMap("name:bingbing;age:33;address:beijing")
结果如下:
1 2 3 4
3、UDAF 用户自定义聚合函数。user defined aggregate function。多对一的输入输出 count sum max。
定义一个UDAF需要如下步骤:
UDF自定义函数必须是org.apache.hadoop.hive.ql.exec.UDAF的子类,并且包含一个或者多个嵌套的的实现了org.apache.hadoop.hive.ql.exec.UDAFEvaluator的静态类。
函数类需要继承UDAF类,内部类Evaluator实UDAFEvaluator接口。
Evaluator需要实现 init、iterate、terminatePartial、merge、terminate这几个函数
这几个函数作用如下:
函数
说明
init
实现接口UDAFEvaluator的init函数
iterate
每次对一个新值进行聚集计算都会调用,计算函数要根据计算的结果更新其内部状态
terminatePartial
无参数,其为iterate函数轮转结束后,返回轮转数据
merge
接收terminatePartial的返回结果,进行数据merge操作,其返回类型为boolean。
terminate
返回最终的聚集函数结果。
案例一 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 package cn.kgc.hive.udaf;import org.apache.hadoop.hive.ql.metadata.HiveException;import org.apache.hadoop.hive.ql.parse.SemanticException;import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;import org.apache.hadoop.hive.serde2.typeinfo.TypeInfoUtils;import java.util.HashMap;import java.util.Map;public class MapCollector extends AbstractGenericUDAFResolver @Override public GenericUDAFEvaluator getEvaluator (TypeInfo[] info) throws SemanticException if (2 != info.length) {throw new SemanticException(" there must be 2 type parameters !!!" );0 ]);1 ]);int not = pt1.getCategory() != ObjectInspector.Category.PRIMITIVE ? 1 : pt2.getCategory() != ObjectInspector.Category.PRIMITIVE ? 2 : 0 ;if (0 != not) {1 ? pt1.getTypeName() : pt2.getTypeName();throw new SemanticException(" only primitive type supported, you provide type of " + type);return new CollectMapper();public static class CollectMapper extends GenericUDAFEvaluator new AggCollect();@Override public ObjectInspector init (Mode m, ObjectInspector[] parameters) throws HiveException super .init(m, parameters);if (m == Mode.PARTIAL1 || m == Mode.COMPLETE) {if (parameters.length != 2 ) {throw new HiveException(" there must be 2 parameters in period of Mapper!!!" );0 ];1 ];else {if (parameters.length != 1 ) {throw new HiveException(" there must be 2 parameters in period of Combiner or Reducer!!!" );0 ];if (m == Mode.COMPLETE || m == Mode.PARTIAL1 || m == Mode.PARTIAL2) {else {return outParam;static class AggCollect implements AggregationBuffer new HashMap();public void add (Object key, Object value) public void reset () public void addAll (AggCollect acParam) @Override public AggregationBuffer getNewAggregationBuffer () throws HiveException return new AggCollect();@Override public void reset (AggregationBuffer aggBuffer) throws HiveException @Override public void iterate (AggregationBuffer aggBuffer, Object[] objects) throws HiveException assert null != aggBuffer && objects.length==2 ;0 ],objects[1 ]);@Override public Object terminatePartial (AggregationBuffer aggBuffer) throws HiveException return aggCollect;@Override public void merge (AggregationBuffer aggBuffer, Object o) throws HiveException @Override public Object terminate (AggregationBuffer aggBuffer) throws HiveException return ((AggCollect)aggBuffer).map;
案例二 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import org.apache.hadoop.hive.ql.exec.UDAF;import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;import org.apache.hadoop.io.IntWritable;public class MaxValueUDAF extends UDAF public static class MaximumIntUDAFEvaluator implements UDAFEvaluator private IntWritable result;public void init () null ;public boolean iterate (IntWritable value) if (value == null ) {return true ;if (result == null ) {new IntWritable( value.get() );else {return true ;public IntWritable terminatePartial () return result;public boolean merge (IntWritable other) return iterate( other );public IntWritable terminate () return result;
打包加载 对上述命令源文件打包为udf.jar,拷贝到服务器的/hivedata/目录
在Hive客户端把udf.jar加入到hive中,如下:
1 add jar /hivedata/udf.jar;
创建临时函数: 在Hive客户端创建函数:
1 2 3 create temporary function maxInt as 'com.qf.hive.MaxValueUDAF' ;show functions;
测试临时函数 1 2 3 4 select maxInt(mgr) from emp7902