Hive数据倾斜的原因和处理

Hive数据倾斜的原因和处理
[TOC]
数据倾斜概念
数据倾斜就是数据的分布不平衡,某些地方特别多,某些地方又特别少,导致的在处理数据的时候,有些很快就处理完了,而有些又迟迟未能处理完,导致整体任务最终迟迟无法完成,这种现象就是数据倾斜。
针对mapreduce的过程来说就是,有多个reduce,其中有一个或者若干个reduce要处理的数据量特别大,而其他的reduce处理的数据量则比较小,那么这些数据量小的reduce很快就可以完成,而数据量大的则需要很多时间,导致整个任务一直在等它而迟迟无法完成。
跑mr任务时常见的reduce的进度总是卡在99%,这种现象很大可能就是数据倾斜造成的。
数据倾斜原理
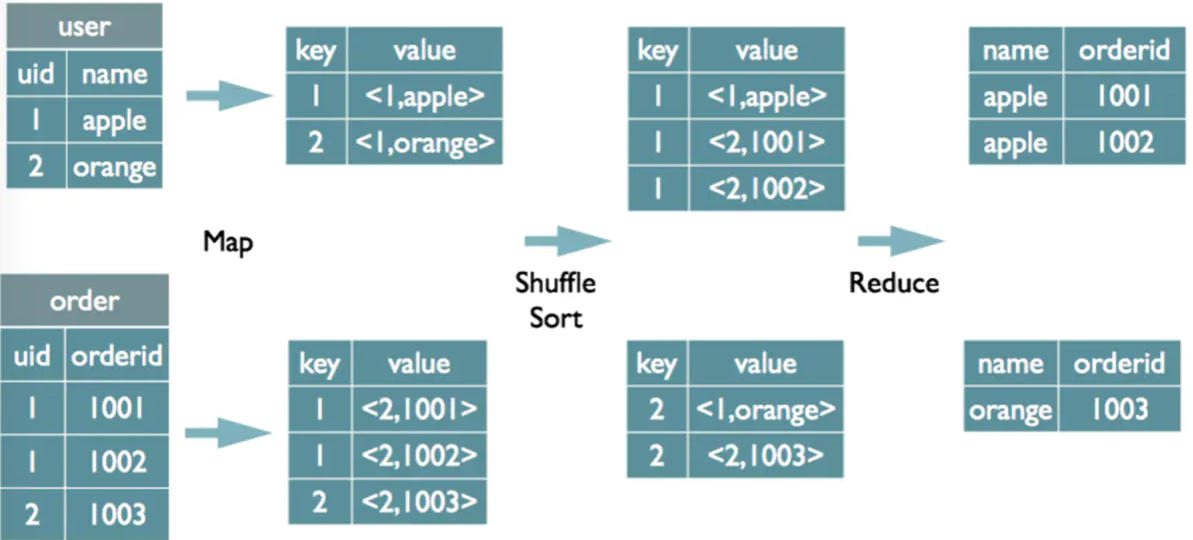
join实现原理
1 | |
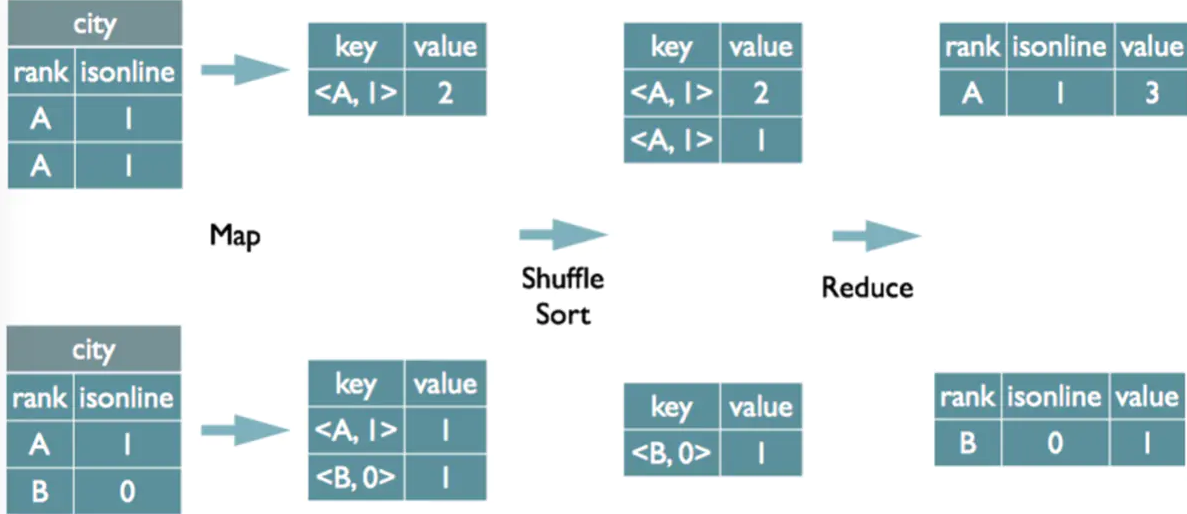
group by 实现原理
1 | |
数据倾斜出现原因
1.key 分布不均匀
2.业务数据本身的特性
3.建表考虑不周全
4.某些 HQL 语句本身就存在数据倾斜,如下所示:

数据倾斜场景及优化方法
一、小表与大表JOIN
场景
小表与大表Join时容易发生数据倾斜,表现为小表的数据量比较少但key却比较集中,导致分发到某一个或几个reduce上的数据比其他reduce多很多,造成数据倾斜。
优化方法
使用Map Join将小表装入内存,在map端完成join操作,这样就避免了reduce操作。有两种方法可以执行Map Join:
(1) 通过hint指定小表做MapJoin
1 | |
(2) 通过配置参数自动做MapJoin
核心参数:
| 参数名称 | 默认值 | 说明 |
|---|---|---|
| hive.auto.convert.join | false | 是否将 common join (reduce 端 join)转换为map join |
| hive.mapjoin.smalltable.filesize | 25000000 | 判断小表的输入文件的大小阈值,默认为25M |
因此,巧用MapJoin可以有效解决小表关联大表场景下的数据倾斜。
二、大表与大表JOIN
场景
大表与大表Join时,当其中一张表的NULL值(或其他值)比较多时,容易导致这些相同值在reduce阶段集中在某一个或几个reduce上,发生数据倾斜问题。
优化方法
(1) Null值合并
将NULL值提取出来最后合并,这一部分只有map操作;非NULL值的数据分散到不同reduce上,不会出现某个reduce任务数据加工时间过长的情况,整体效率提升明显。这种方法由于有两次Table Scan会导致map增多。
1 | |
(2) Null给定随机值
在Join时直接把NULL值打散成随机值来作为reduce的key值,不会出现某个reduce任务数据加工时间过长的情况,整体效率提升明显。这种方法解释计划只有一次map,效率一般优于第一种方法。
1 | |
三、GROUP BY 操作
场景
Hive做group by查询,当遇到group by字段的某些值特别多的时候,会将相同值拉到同一个reduce任务进行聚合,也容易发生数据倾斜。
优化方法
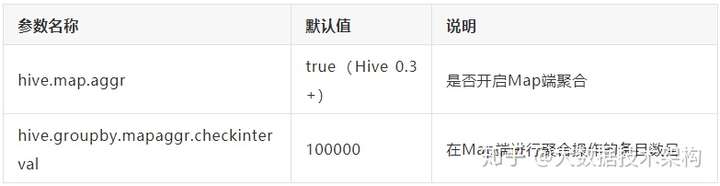
(1) 开启Map端聚合
参数设置:
(2) 有数据倾斜时进行负载均衡
参数设置:

当设定hive.groupby.skewindata为true时,生成的查询计划会有两个MapReduce任务。在第一个MapReduce 中,map的输出结果集合会随机分布到 reduce 中, 每个 reduce 做部分聚合操作,这样处理之后,相同的 Group By Key 有可能分发到不同的 reduce 中,从而达到负载均衡的目的。在第二个 MapReduce 任务再根据第一步中处理的数据按照Group By Key分布到reduce中,(这一步中相同的key在同一个reduce中),最终生成聚合操作结果。
四、COUNT(DISTINCT) 操作
场景
当在数据量比较大的情况下,由于COUNT DISTINCT操作是用一个reduce任务来完成,这一个reduce需要处理的数据量太大,就会导致整个job很难完成,这也可以归纳为一种数据倾斜。
优化方法
(1)使用GroupBy
将COUNT DISTINCT使用先GROUP BY再COUNT的方式替换。例如:
1 | |
因此,count distinct的优化本质上也是转成group by操作。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!