MySQL三范式详解
[TOC]
设计关系型数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。
目前关系型数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。一般来说,数据库只需要满足第三范式就行了。
第一范式:保证每列的原子性
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库满足了第一范式。
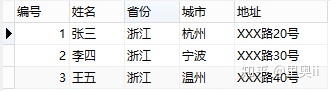
第一范式需要根据系统的实际需求的业务来定,比如有一张用户信息表:

一般来说”住址”设计成一个字段就行,但是如果经常访问”住址”中城市的部分,那么就非要将”住址”这个属性重新拆分为”省份”、”城市”、”地址”等多个部分进行存储,这样在对”住址”中某一部分进行操作的时候将非常方便。这么设计才算满足了数据库的第一范式,修改之后的表结构如图:
第二范式:保证一张表只描述一件事情
这是通俗的说法,用第二范式的定义描述第二范式,说的是在满足第一范式的基础上,数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖,也即所有非关键字段都完全依赖于任一组候选关键字。
看不懂是吗,没关系,我也看不懂,下面举一个例子,有一张表如下图:
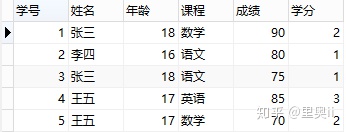
上表满足第一范式,即每个字段不可再分,但是这张表设计得并不好,或者说,这张表的设计并不满足第二范式。因为这张表里面描述了两件事情:学生信息、课程信息,”学分”完全依赖于”课程名称”、”姓名”与”年龄”完全依赖于”学号”。这么做的后果是:
1、数据冗余:同一门课程由n个学生选修,”学分”重复n-1次;同一个学生选修了m门课程,姓名和年龄重复m-1次
2、更新异常:若调整了某门课程的学分,数据表中所有行的”学分”值都需要更新,否则会出现同一门课程学分不同的情况
3、插入异常:假设要开一门新课程,暂时没有人选修,那么由于没有”学号”关键字,”课程”与”学分”也无法记录入数据库
4、删除异常:假设一批学生已经完成课程的选修,这些选修记录就应该从数据库表中删除。但是,与此同时,”课程”和”学分”也被删除了,显然,这最终可能会导致插入异常
所以,此表的结构必须修改,修改后如下:
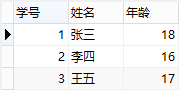
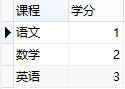
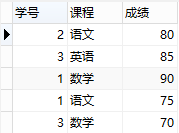
增加了表,将学生信息与课程信息通过一张中间表关联,很好地解决了上面的几个问题,这就是第二范式的中心—-保证一张表只讲一件事情。
第三范式—-保证每列都和主键直接相关
第三范式又和第二范式相关,用第三范式的定义描述第三范式就是,数据库表中如果不存在非关键字段任一候选关键字段的传递函数依赖则符合第三范式,所谓传递函数依赖指的是如果存在”A–>B–>C”的决定关系,则C传递函数依赖于A。也就是说表中的字段和主键直接对应不依靠其他中间字段,说白了就是,决定某字段值的必须是主键。
举个例子,看一下如下的表结构:
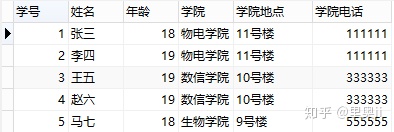
第三范式和第二范式有点像,从这张数据库表结构中可以看出,”姓名”、”年龄”、”学院”和主键”学号”直接关联,但是”学院地点”、”学院电话”却不直接和主键”学号”相关联,和”学院电话”直接相关联的是”学院”,如果表结构这么设计,同样会造成和第二范式一样的数据冗余、更新异常、插入异常、删除异常的问题。
修改之后的表结构如下图:

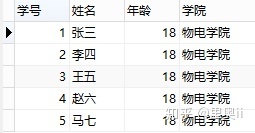
同样,这么设计表结构将合理地多,也解决了前面的四个问题。
简单的来说:第三范式就是在第二范式的基础上消除传递依赖,让表中的所有列直接依赖于主键。而且通常主键的大多为自增列,自增列的好处太多了,主要的好处就是便于后数据库的维护:
- 本身无意义
- 插入数据时,若不为自增列,主键列的物理顺序须为有序,当乱序插入会产生多个磁盘碎片,整理耗费时间,寻址浪费时间
- 自增列反之,本身有序,利于管理;
- 自增列不会重复,满足主键不为空;
- 自增列不会为null,满足主键不为空;
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!